
AI-Generated Scannable QR Code Images - New ControlNet Model Showcase
Introduction
It's been a while since I've updated my public account. Today I'm sharing a new creation: ControlNet for QR Code
What are the effects? What's it useful for? Let's look at the examples below.
This is an ordinary, seemingly chaotic Stable Diffusion-generated stylized image:

But after adding three positioning points, this image becomes a scannable QR code:

Press and hold to scan the QR code, which will redirect to qrbtf.com
Amazing, right? Below is the project's origin, training process, and more generation results...
Origins
During my sophomore year, my classmate and I created a parametric QR code generator, qrbtf.com (How to Make a Beautiful QR Code). For various reasons (procrastination), it hasn't been updated since. I remember during a conversation with Mr. Yonggang from Innovation Works, we suddenly discussed whether it would be possible to encode hidden information in any visually normal image. In that GAN era, the machine learning ecosystem was far less active than today. Without frameworks like Gradio Web UI and Diffusers, just setting up the environment was enough to discourage me, so this idea was shelved.
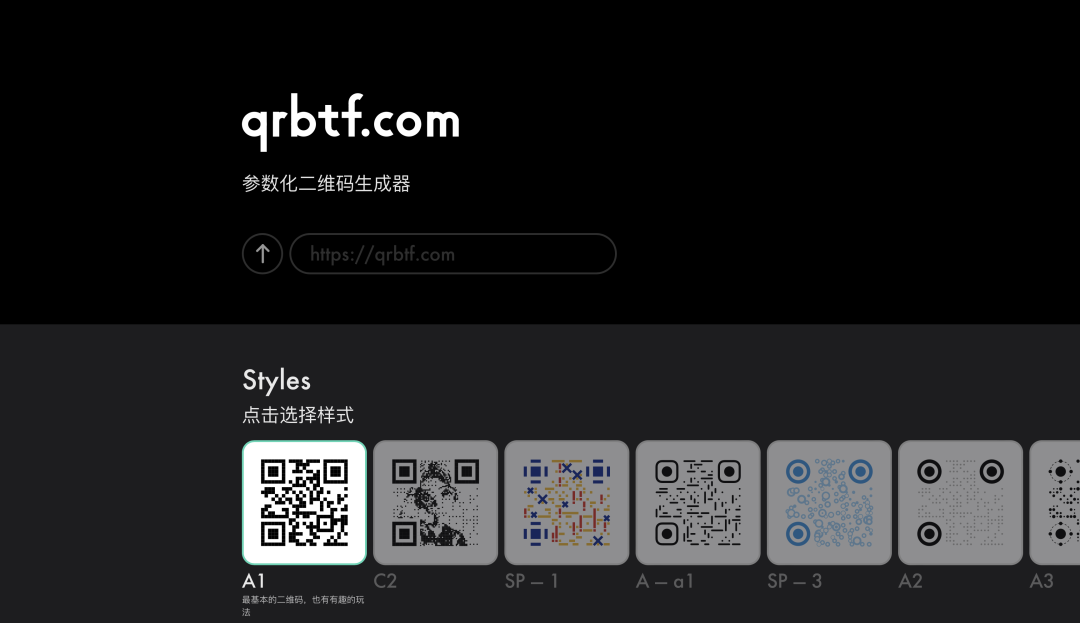
Until Stable Diffusion emerged and ControlNet swept across various industries, after a long period of exploration, I finally reopened this project - could we use diffusion models to generate a QR code that looks like an actual image?

Initial ControlNet attempt
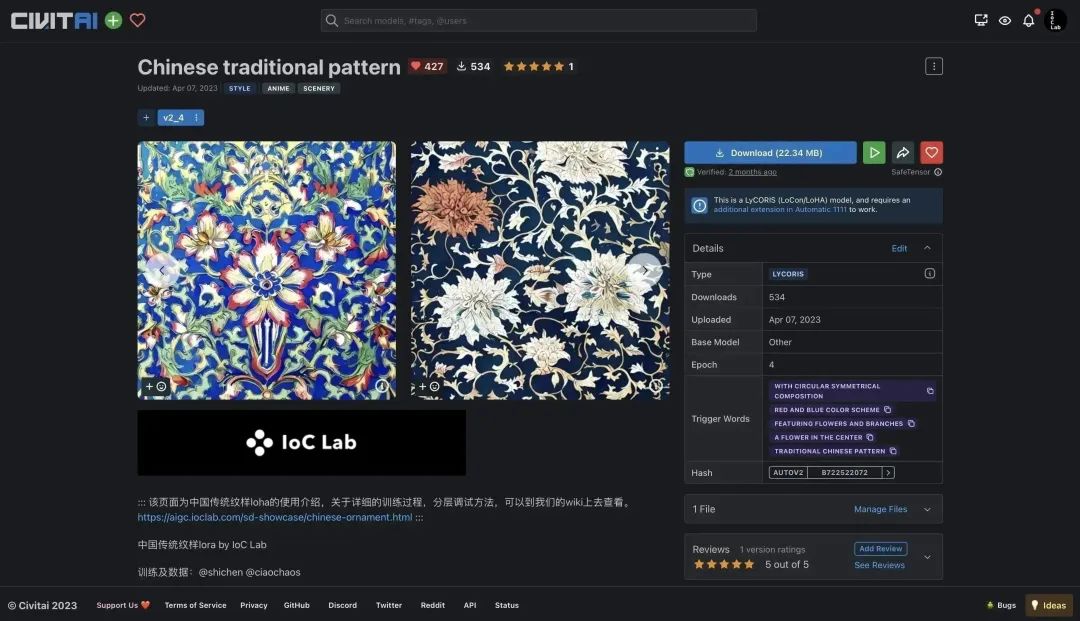
Training Chinese traditional pattern LoRA
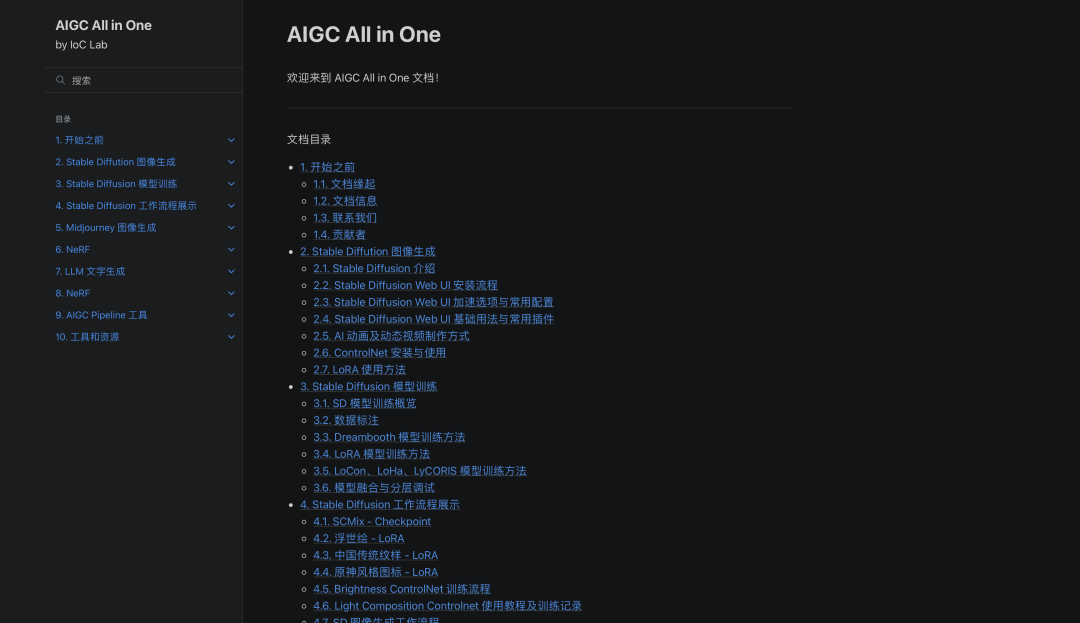
AIGC All in One documentation, continuously updating

HuggingFace JAX/Diffusers Sprint
Training
The data structure for ControlNet training is very simple, consisting only of an input image (conditioning image), an output image (image), and a caption. The official release provided many pre-trained models, including Depth, HED, OpenPose from version 1.0, and the very creative Shuffle, Tile, and Instruct Pix2Pix from version 1.1.
ControlNet training has high requirements for both data volume and computing power. The paper recorded training data volumes ranging from 80,000 to 3 million, with training times reaching 600 A100 GPU hours. Fortunately, the author provided basic training scripts, and HuggingFace also implemented it in Diffusers.
During the previous JAX Sprint, we were fortunate to use Google TPU v4, quickly completing the training of 3 million images. Unfortunately, after the event ended, we returned to our lab's A6000/4090, training a 100,000-image version with a very high learning rate, just to achieve "sudden convergence" as early as possible.
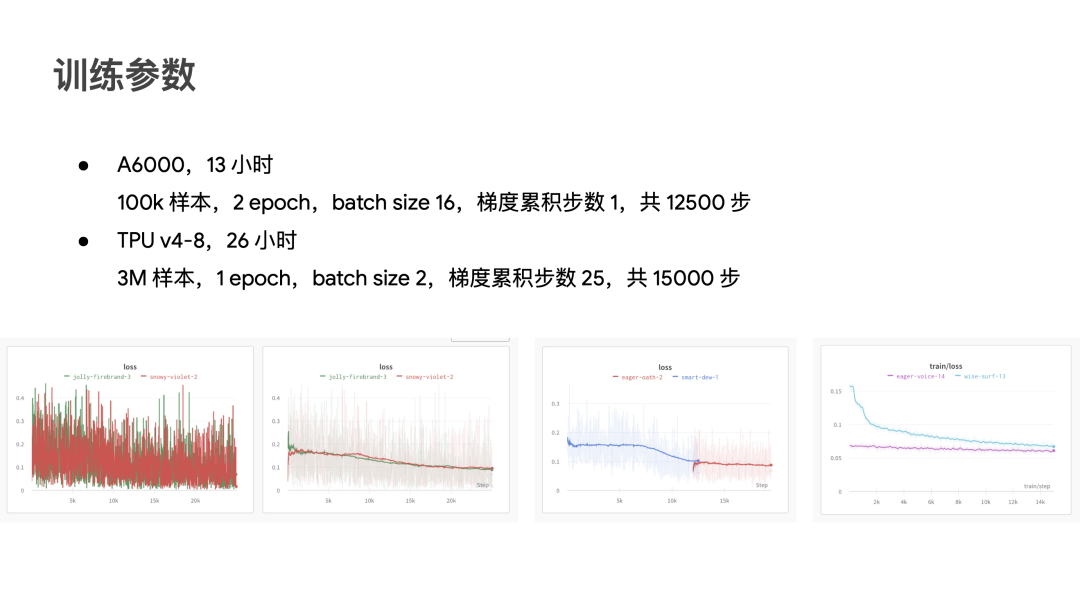
GPU/TPU training parameters
Grayscale control ControlNet, training process at aigc.ioclab.com/sd-showcase/brightness-controlnet

Light control ControlNet, training process at aigc.ioclab.com/sd-showcase/light_controlnet
Inference
After testing the model training, we tried various combinations of Checkpoint + LoRA + QR Code ControlNet. We obtained various recognizable QR codes as shown below.
Chinese Traditional Patterns
LoRA training process: aigc.ioclab.com/sd-showcase/chinese-ornament LoRA model download: civitai.com/models/29858/chinese-traditional-pattern



Ukiyo-e Style
LoRA training process: aigc.ioclab.com/sd-showcase/fuyue LoRA model download: civitai.com/models/25222/ukiyo-e-fuyue-style-background-mix



Anime and Illustration Style








Ink Style (MoXin)

Watercolor Style

3D Style




Abstract Style


PCB Style


Bonus: Photoshop Redraw


Afterword
As I graduate from college, with the pandemic subsiding and seeing such vigorous development in generative AI, I can't help but wish I could do my undergraduate studies again.
This QR Code ControlNet project wouldn't have been possible without the collaborative efforts of ![]() Shichen
Shichen ![]() Zhaohan Wang
Zhaohan Wang ![]() CPunisher, who together completed the dataset preparation, training, and inference testing within three days, as well as the GPU resource support from Professor Lu Xin and Professor Sun Guoyu's laboratories. We also want to sincerely thank Google and HuggingFace for their generous provision of TPU servers earlier, which was truly enjoyable.
CPunisher, who together completed the dataset preparation, training, and inference testing within three days, as well as the GPU resource support from Professor Lu Xin and Professor Sun Guoyu's laboratories. We also want to sincerely thank Google and HuggingFace for their generous provision of TPU servers earlier, which was truly enjoyable.
For model release and technical documentation, please stay tuned for subsequent updates on the public account and documentation updates (aigc.latentcat.com). Welcome to click "Read Original" to comment on the documentation!