Introduction
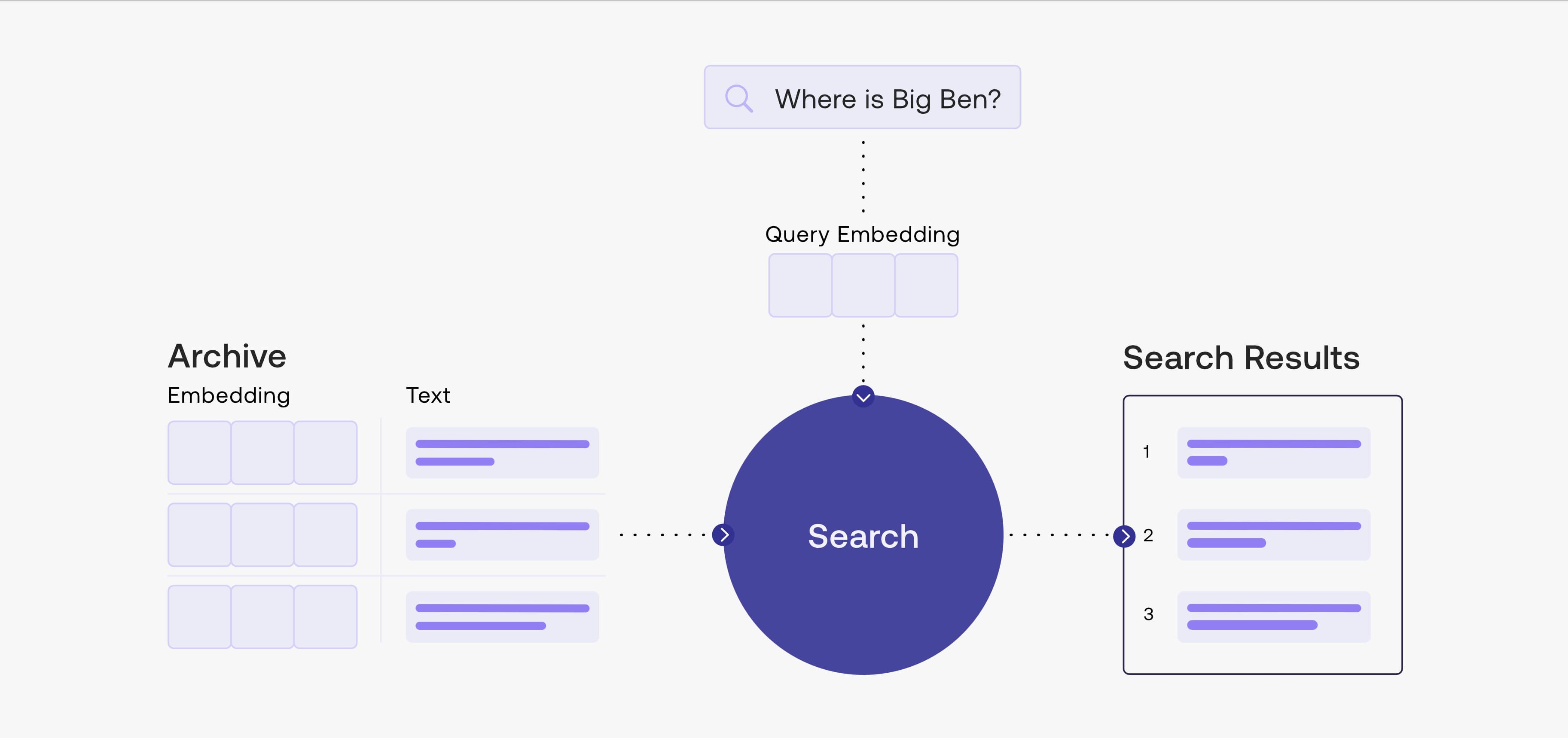
Semantic search is a crucial component in LLM engineering. It can match massive amounts of text data through feature vectors, allowing LLMs to "break through" token quantity limitations and access more extensive information. This article will demonstrate a basic implementation of this technology using LangChain + Gradio + FAISS. Below is ChatGPT's explanation of Embedding vector search and Cohere's semantic search framework diagram.
Embedding vector search is a search technique based on the vector space model that achieves text similarity comparison by converting text into vector form. Specifically, Embedding vector search first preprocesses and extracts features from text, outputs text as fixed-length vectors, then measures similarity between these vectors in vector space to find text vectors most similar to the query vector, thus completing the search task. This technology is widely applied in fields such as natural language processing, social network analysis, and image search. Its advantage is that it can quickly search for results most similar to the query vector while efficiently processing multi-parameter queries. Its disadvantage is that for very complex text meanings, the semantic information extracted may be limited, and accuracy issues can easily arise.
Data Preparation
Taking the Friends complete series data from ConvoKit as an example, we'll download and process the data into TXT and Excel formats for viewing and subsequent use.
Install ConvoKit:
pip install convokit
Import packages:
from convokit import Corpus, download
Download data:
corpus = Corpus(download('friends-corpus'))
corpus.print_summary_stats()
Write data to files:
for convo_index, convo in enumerate(corpus.iter_conversations()):
season = convo.meta['season']
episode = convo.meta['episode']
scene = convo.meta['scene']
self.write_txt_line(f"- SEASON: {season}; \n- EPISODE: {episode}; \n- SCENE: {scene}")
for utt_index, utt in enumerate(convo.iter_utterances()):
role = ""
content = ""
if utt.speaker.id == "TRANSCRIPT_NOTE":
role = "TRANSCRIPT_NOTE"
content = utt.meta['transcript_with_note']
else:
role = utt.speaker.id
content = utt.text
self.write_xlsx_line([season, episode, scene], role, content)
self.write_txt_line(f"{role}: {content}")
View data:

Building the Embedding Database
This section will split the text data, convert it to vectors using the OpenAI Ada embedding model, and store it in a database.
Import dependencies:
from langchain import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
import pickle
Set API Key:
import os
os.environ['OPENAI_API_KEY'] = ''
Split text by sentences using separator "\n\n":
IN_DIR = './text_source'
filename = 'friends-corpus'
with open(f'./{IN_DIR}/{filename}.txt') as f:
file = f.read()
text_splitter = CharacterTextSplitter(separator='\n\n', chunk_size=0, chunk_overlap=0)
texts = text_splitter.split_text(file)
Or split text by script scenes using separator "---":
text_splitter = CharacterTextSplitter(separator='---', chunk_size=0, chunk_overlap=0)
texts = text_splitter.split_text(file)
Build vector database using OpenAI's Ada model and FAISS:
OUT_DIR = './vector_db_out'
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_texts(texts, embeddings)
Serialize database object to binary using pickle:
with open(f"{OUT_DIR}/{filename}.pkl", "wb") as f:
pickle.dump(vector_store, f)
Query and Gradio UI
Build query webpage through Gradio web UI.
Deserialize binary back to Python object:
with open(f"{OUT_DIR}/{filename}.pkl", "rb") as f:
vector_store = pickle.load(f)
Install and import Gradio:
pip install gradio
import gradio as gr
Query function:
def question_answer(self, question, num_result):
docs = vector_store.similarity_search_with_score(question, k=num_result)
result = [[str(round(score, 3)), doc.page_content] for doc, score in docs]
return result
Define and launch Gradio:
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
prompt = gr.Textbox(
label="Prompt",
)
num_result = gr.Slider(
1, 200, 50,
step=1,
label="Number of Results",
)
submit_btn = gr.Button(
label="Search"
)
with gr.Column():
output = gr.Dataframe(
headers=["Score", "Content"],
datatype=["str", "markdown"]
)
submit_btn.click(
fn=question_answer,
inputs=[
prompt, num_result
],
outputs=output
)
demo.launch(
server_name="0.0.0.0",
server_port=7010
)
Test Results
Below are tests using Friends, Genshin Impact, and Douban Movie data for learning reference only. All data comes from GitHub.



")
")
