はじめに
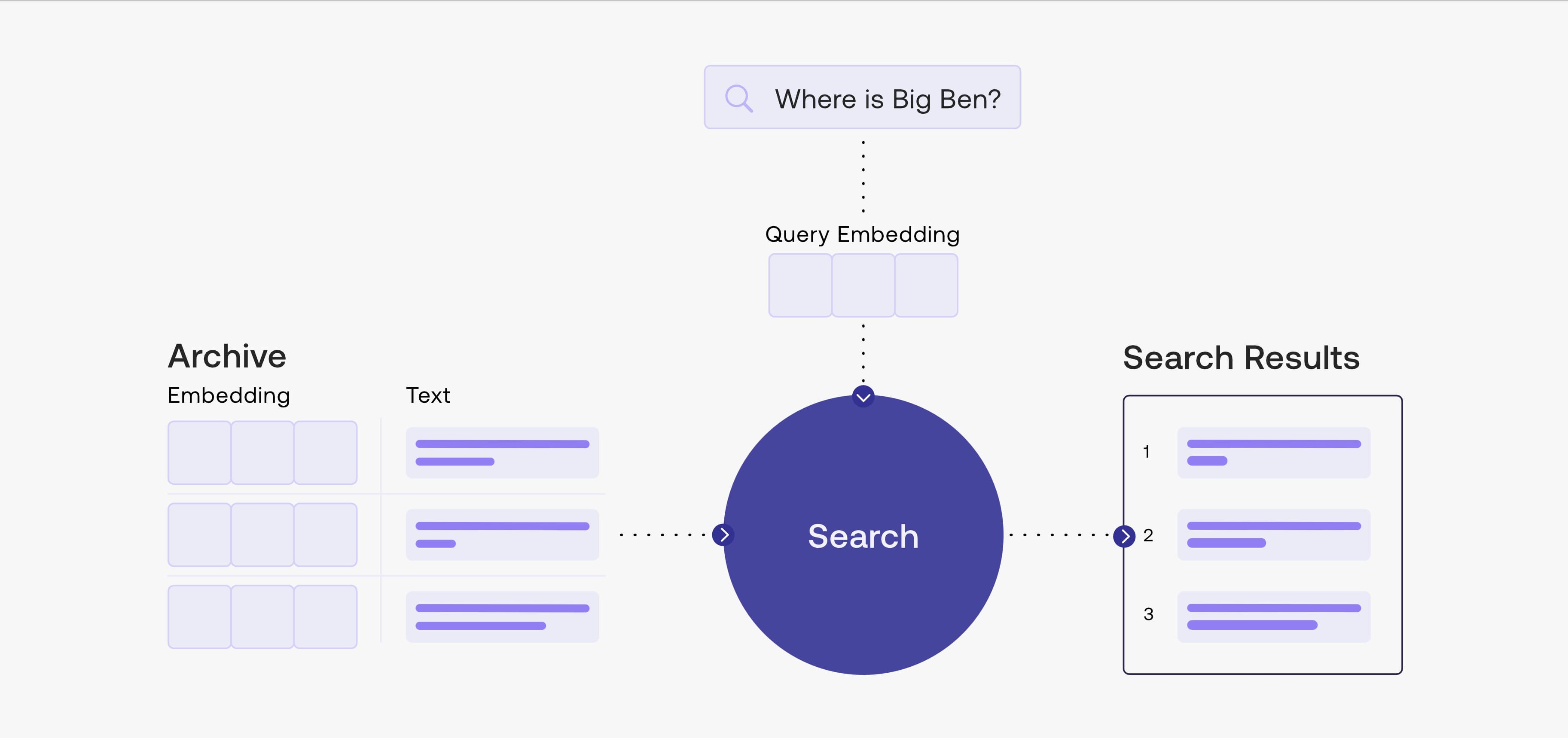
意味検索は LLM エンジニアリングにおける重要な要素です。特徴ベクトルを使用して大量のテキストデータをマッチングし、LLM が token 数の制限を「突破」して、より大量の情報にアクセスすることを可能にします。本記事では、LangChain + Gradio + FAISS を使用してこの技術の基本的な実装を行います。以下は Embedding ベクトル検索に関する ChatGPT の説明と、cohere の意味検索フレームワークの図です。
Embedding ベクトル検索は、ベクトル空間モデルに基づく検索技術で、テキストをベクトル形式に変換することでテキストの類似度比較を実現します。具体的には、Embedding ベクトル検索はまずテキストの前処理と特徴抽出を行い、テキストを固定長のベクトルとして出力し、次にベクトル空間でこれらのベクトル間の類似度を測定し、クエリベクトルに最も類似したテキストベクトルを見つけることで検索タスクを完了します。この技術は自然言語処理、ソーシャルネットワーク分析、画像検索など、幅広い分野で応用されています。クエリベクトルに最も類似した結果を素早く検索でき、複数パラメータのクエリを効率的に処理できる利点がありますが、テキストの意味が非常に複雑な場合、抽出される意味情報が限定的で精度の問題が生じやすい欠点があります。
データの準備
ConvoKit のフレンズ全シリーズデータを例に、データをダウンロードして TXT、Excel 形式に処理し、閲覧と後続の使用に便利にします。
ConvoKit のインストール:
pip install convokit
パッケージのインポート:
from convokit import Corpus, download
データのダウンロード:
corpus = Corpus(download('friends-corpus'))
corpus.print_summary_stats()
データをファイルに書き込む:
for convo_index, convo in enumerate(corpus.iter_conversations()):
season = convo.meta['season']
episode = convo.meta['episode']
scene = convo.meta['scene']
self.write_txt_line(f"- SEASON: {season}; \n- EPISODE: {episode}; \n- SCENE: {scene}")
for utt_index, utt in enumerate(convo.iter_utterances()):
role = ""
content = ""
if utt.speaker.id == "TRANSCRIPT_NOTE":
role = "TRANSCRIPT_NOTE"
content = utt.meta['transcript_with_note']
else:
role = utt.speaker.id
content = utt.text
self.write_xlsx_line([season, episode, scene], role, content)
self.write_txt_line(f"{role}: {content}")
データの確認:

Embedding データベースの構築
このセクションでは、テキストデータを分割し、OpenAI Ada embedding モデルを使用してベクトルに変換し、データベースに保存します。
依存関係のインポート:
from langchain import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
import pickle
API Key の設定:
import os
os.environ['OPENAI_API_KEY'] = ''
区切り文字 "\n\n" を使用して文単位でテキストを分割:
IN_DIR = './text_source'
filename = 'friends-corpus'
with open(f'./{IN_DIR}/{filename}.txt') as f:
file = f.read()
text_splitter = CharacterTextSplitter(separator='\n\n', chunk_size=0, chunk_overlap=0)
texts = text_splitter.split_text(file)
または区切り文字 "---" を使用してシーン単位でテキストを分割:
text_splitter = CharacterTextSplitter(separator='---', chunk_size=0, chunk_overlap=0)
texts = text_splitter.split_text(file)
OpenAI の Ada モデルと FAISS を使用してベクトルデータベースを構築:
OUT_DIR = './vector_db_out'
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_texts(texts, embeddings)
pickle を使用してデータベースオブジェクトをバイナリにシリアライズ:
with open(f"{OUT_DIR}/{filename}.pkl", "wb") as f:
pickle.dump(vector_store, f)
クエリと Gradio UI
Gradio web UI を通じてクエリウェブページを構築します。
バイナリを Python オブジェクトに逆シリアライズ:
with open(f"{OUT_DIR}/{filename}.pkl", "rb") as f:
vector_store = pickle.load(f)
Gradio のインストールとインポート:
pip install gradio
import gradio as gr
クエリ関数:
def question_answer(self, question, num_result):
docs = vector_store.similarity_search_with_score(question, k=num_result)
result = [[str(round(score, 3)), doc.page_content] for doc, score in docs]
return result
Gradio の定義と起動:
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
prompt = gr.Textbox(
label="Prompt",
)
num_result = gr.Slider(
1, 200, 50,
step=1,
label="結果数",
)
submit_btn = gr.Button(
label="検索"
)
with gr.Column():
output = gr.Dataframe(
headers=["Score", "Content"],
datatype=["str", "markdown"]
)
submit_btn.click(
fn=question_answer,
inputs=[
prompt, num_result
],
outputs=output
)
demo.launch(
server_name="0.0.0.0",
server_port=7010
)
テスト結果
以下はフレンズ、原神、豆瓣映画データのテストで、学習参考用です。データはすべて GitHub からのものです。



")
")
